
 SQL语句
SQL语句
# SQL语句
# 1. SQL概述
# 1.1 SQL背景知识
1946 年,世界上第一台电脑诞生,如今,借由这台电脑发展起来的互联网已经自成江湖。在这几十年里,无数的技术、产业在这片江湖里沉浮,有的方兴未艾,有的已经几幕兴衰。但在这片浩荡的波动里,有一门技术从未消失,甚至“老当益壮”,那就是 SQL。
- 45 年前,也就是 1974 年,IBM 研究员发布了一篇揭开数据库技术的论文《SEQUEL:一门结构化的英语查询语言》,直到今天这门结构化的查询语言并没有太大的变化,相比于其他语言,
SQL 的半衰期可以说是非常长了。
- 45 年前,也就是 1974 年,IBM 研究员发布了一篇揭开数据库技术的论文《SEQUEL:一门结构化的英语查询语言》,直到今天这门结构化的查询语言并没有太大的变化,相比于其他语言,
不论是前端工程师,还是后端算法工程师,都一定会和数据打交道,都需要了解如何又快又准确地提取自己想要的数据。更别提数据分析师了,他们的工作就是和数据打交道,整理不同的报告,以便指导业务决策。
- 数据结构和算发是在内存级别进行数据存储运算。
- 数据持久化层面存储,需要用到数据库。
SQL(Structured Query Language,结构化查询语言)是使用关系模型的数据库应用语言, 与数据直接打交道 ,由 IBM 上世纪70年代开发出来。后由美国国家标准局(ANSI)开始着手制定SQL标准,先后有
SQL-86,SQL-89,SQL-92,SQL-99等标准。- SQL 有两个重要的标准,分别是 SQL92 和 SQL99,它们分别代表了 92 年和 99 年颁布的 SQL 标准,我们今天使用的 SQL 语言依然遵循这些标准。
不同的数据库生产厂商都支持SQL语句,但都有特有内容。
# 1.2 TIOBE 编程语言排行榜
TIOBE Index - TIOBE (opens new window)
# 1.3 SQL分类
SQL语言在功能上主要分为如下3大类:
DDL(Data Definition Languages、数据定义语言),这些语句定义了不同的数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。- 主要的语句关键字包括
CREATE、DROP、ALTER等。
- 主要的语句关键字包括
DML(Data Manipulation Language、数据操作语言),用于添加、删除、更新和查询数据库记录,并检查数据完整性。- 主要的语句关键字包括
INSERT、DELETE、UPDATE、SELECT等。- - SELECT是SQL语言的基础,最为重要。
- 主要的语句关键字包括
DCL(Data Control Language、数据控制语言),用于定义数据库、表、字段、用户的访问权限和安全级别。- 主要的语句关键字包括
GRANT、REVOKE、COMMIT、ROLLBACK、SAVEPOINT等。
- 主要的语句关键字包括
因为查询语句使用的非常的频繁,所以很多人把查询语句单拎出来一类:DQL(数据查询语言)。还有单独将 COMMIT 、 ROLLBACK 取出来称为TCL (Transaction Control Language,事务控制语言)。
# 2. SQL语言的规则与规范
# 2.1 基本规则
必须遵守
SQL 可以写在一行或者多行。为了提高可读性,各子句分行写,必要时使用缩进。
每条命令以 ; 或 \g 或 \G 结束。
关键字不能被缩写也不能分行。
关于标点符号
- 必须保证所有的()、单引号、双引号是成对结束的
- 必须使用英文状态下的半角输入方式
- 字符串型和日期时间类型的数据可以使用单引号(' ')表示
- 列的别名,尽量使用双引号(" "),而且不建议省略as
# 2.2 SQL大小写规范
建议遵守
MySQL 在Windows环境下是大小写不敏感的MySQL 在 Linux 环境下是大小写敏感的- 数据库名、表名、表的别名、变量名是严格区分大小写的
- 关键字、函数名、列名(或字段名)、列的别名(字段的别名) 是忽略大小写的。
推荐采用统一的书写规范:
- 数据库名、表名、表别名、字段名、字段别名等都小写
- SQL 关键字、函数名、绑定变量等都大写
# 2.3 注释
单行注释:#注释文字(MySQL特有的方式)
单行注释:-- 注释文字(--后面必须包含一个空格。)
多行注释:/* 注释文字 */
2
3
# 2.4 命名规则
数据库、表名不得超过30个字符,变量名限制为29个。
必须只能包含 A–Z, a–z, 0–9, _共63个字符。
数据库名、表名、字段名等对象名中间不要包含空格。
同一个MySQL软件中,数据库不能同名;同一个库中,表不能重名;同一个表中,字段不能重名。
必须保证你的字段没有和保留字、数据库系统或常用方法冲突。如果坚持使用,请在SQL语句中使用`(着重号)引起来。
保持字段名和类型的一致性,在命名字段并为其指定数据类型的时候一定要保证一致性。假如数据类型在一个表里是整数,那在另一个表里可就别变成字符型了。
#以下两句是一样的,不区分大小写
show databases;
SHOW DATABASES;
#创建表格
#create table student info(...); #表名错误,因为表名有空格
create table student_info(...);
#其中order使用``飘号,因为order和系统关键字或系统函数名等预定义标识符重名了
CREATE TABLE `order`(
select id as "编号", `name` as "姓名" from t_stu; #起别名时,as都可以省略
select id as 编号, `name` as 姓名 from t_stu; #如果字段别名中没有空格,那么可以省略""
select id as 编 号, `name` as 姓 名 from t_stu; #错误,如果字段别名中有空格,那么不能省略""
2
3
4
5
6
7
8
9
10
11
12
13
# 2.5 数据导入
# 通过命令行指令
在命令行客户端登录mysql,使用source指令导入
source d:\test.sql # 全路径
示例
mysql> show databases; # 查询数据库
+--------------------+
| Database |
+--------------------+
| dbtest2 |
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> source D:\Project\learn\MySQL\SQL\test.sql # 数据导入
mysql> show databases; # 查询数据库
+--------------------+
| Database |
+--------------------+
| dbtest |
| dbtest2 |
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> use dbtest; # 使用数据库
Database changed
mysql> show tables; # 展示数据库所有表
+------------------+
| Tables_in_dbtest |
+------------------+
| countries |
| departments |
| emp_details_view |
| employees |
| job_grades |
| job_history |
| jobs |
| locations |
| order |
| regions |
+------------------+
10 rows in set (0.00 sec)
mysql> desc employees;
+----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+-------------+------+-----+---------+-------+
| employee_id | int | NO | PRI | 0 | |
| first_name | varchar(20) | YES | | NULL | |
| last_name | varchar(25) | NO | | NULL | |
| email | varchar(25) | NO | UNI | NULL | |
| phone_number | varchar(20) | YES | | NULL | |
| hire_date | date | NO | | NULL | |
| job_id | varchar(10) | NO | MUL | NULL | |
| salary | double(8,2) | YES | | NULL | |
| commission_pct | double(2,2) | YES | | NULL | |
| manager_id | int | YES | MUL | NULL | |
| department_id | int | YES | MUL | NULL | |
+----------------+-------------+------+-----+---------+-------+
11 rows in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
# 基于具体的图形化界面的工具导入
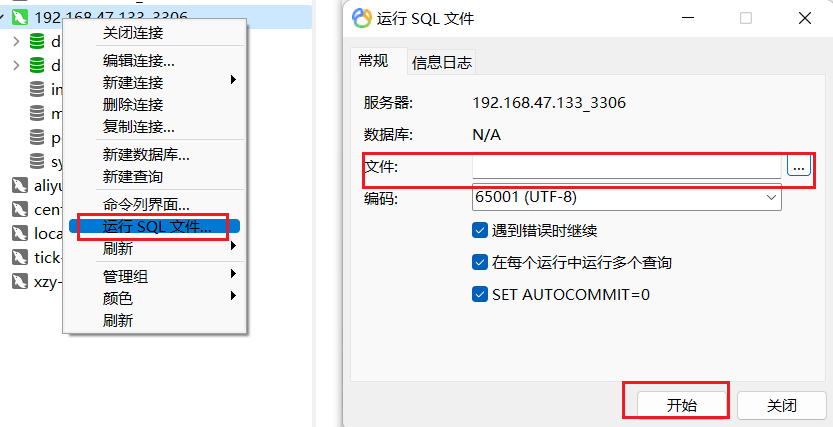
- navicat: 选中数据库右键--点击
运行SQL文件--选择执行的SQL文件,点击确认按钮。
- SQLyog:选择工具--执行的脚本
# 2.6 显示表结构
使用DESCRIBE 或 DESC 命令,表示表结构。
DESCRIBE employees;
或
DESC employees;
mysql> desc employees;
+----------------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------+-------------+------+-----+---------+-------+
| employee_id | int(6) | NO | PRI | 0 | |
| first_name | varchar(20) | YES | | NULL | |
| last_name | varchar(25) | NO | | NULL | |
| email | varchar(25) | NO | UNI | NULL | |
| phone_number | varchar(20) | YES | | NULL | |
| hire_date | date | NO | | NULL | |
| job_id | varchar(10) | NO | MUL | NULL | |
| salary | double(8,2) | YES | | NULL | |
| commission_pct | double(2,2) | YES | | NULL | |
| manager_id | int(6) | YES | MUL | NULL | |
| department_id | int(4) | YES | MUL | NULL | |
+----------------+-------------+------+-----+---------+-------+
11 rows in set (0.00 sec)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
其中,各个字段的含义分别解释如下:
Field:表示字段名称。
Type:表示字段类型,这里 barcode、goodsname 是文本型的,price 是整数类型的。
Null:表示该列是否可以存储NULL值。
Key:表示该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一部分;MUL表示在列中某个给定值允许出现多次。
Default:表示该列是否有默认值,如果有,那么值是多少。
Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等。
 豫公网安备 41048202000165号
豫公网安备 41048202000165号