
 ElasticSearch-概述和安装
ElasticSearch-概述和安装
# ElasticSearch-概述和安装
本次ElasticSearch版本
ElasticSearch7.6.1,Java版本Java8环境资源 :
链接:地址 (opens new window) 提取码:h7n4
# 1. ElasticSearch概述
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别(大数据时代)的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
# 2. ES安装
声明:JDK1.8 ,最低要求! ElasticSearch 客户端,界面工具!
Java开发,ElasticSearch 的版本和我们之后对应的 Java 的核心jar包! 版本对应!JDK 环境是正常!
# 2.1 下载


# 2.2 安装
# 解压即可
# 目录结构

功能
bin 启动文件
config 配置文件
log4j2 日志配置文件
jvm.options java 虚拟机相关的配置 配置ES内存参数
elasticsearch.yml elasticsearch 的配置文件! 默认 9200 端口! 跨域!
lib 相关jar包
logs 日志!
modules 功能模块
plugins 插件!
2
3
4
5
6
7
8
9
# 启动
双击 bin 目录下的 elasticsearch.bat 启动ES

使用Java版本,需要
Java11,这里使用Java8.
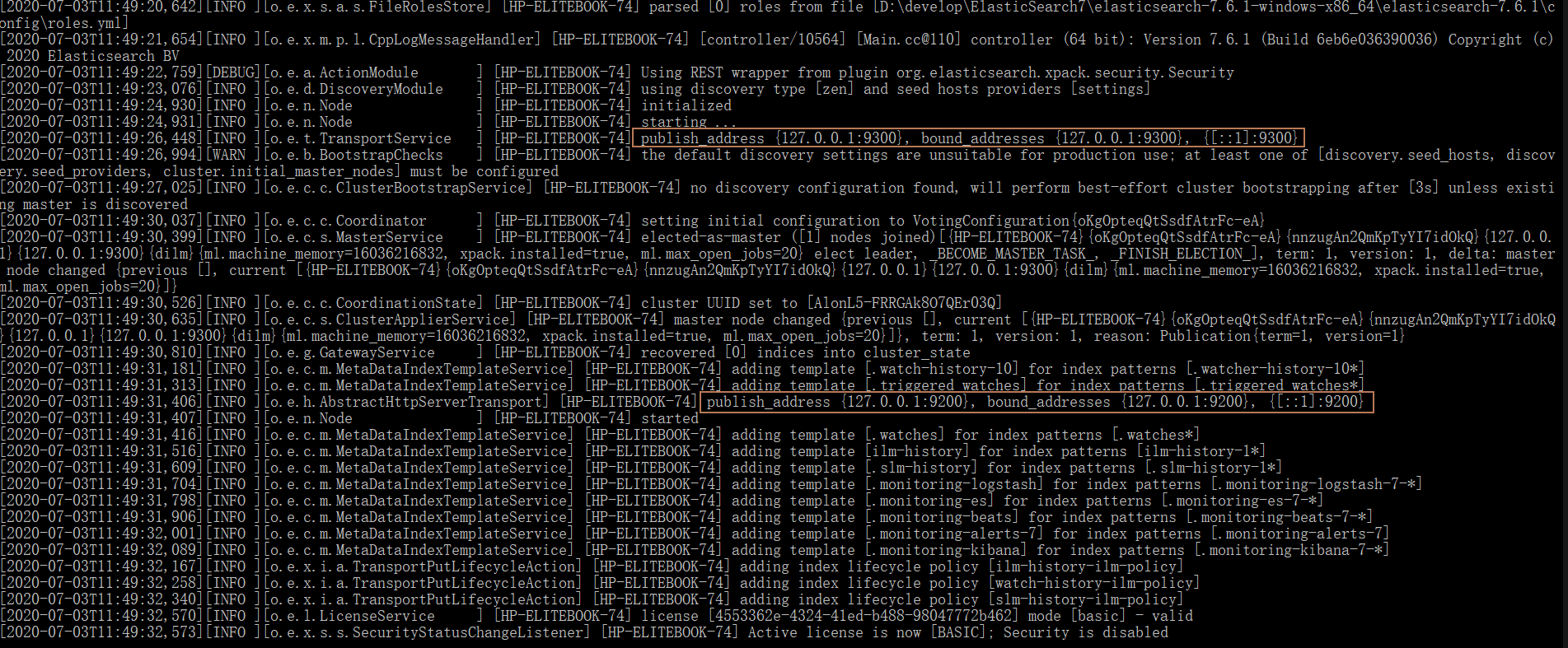
默认端口号: 9200
通信端口号: 9300
# 访问
地址 http://localhost:9200/

# 2.3 安装可视化界面 es head的插件
# 下载地址 (opens new window)
此项目需要环境 node.js ,npm
# 启动
npm install
npm run start
2
# 连接测试
访问 http://localhost:9100/

存在跨域问题:
- 配置es, 修改
elasticsearch.yaml添加如下:
http.cors.enabled: true
http.cors.allow-origin: "*"
2
# 重启es服务器,然后再次连接

这个head我们就把它当做数据展示工具!我们后面所有的查询,使用
Kibana!
# 2.4 了解 ELK
ELK是Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为Elastic Stack。
Elasticsearch是一个基于Lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用Elasticsearch作为底层支持框架,可见Elasticsearch提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。
Logstash是ELK的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。Kibana可以将elasticsearch的数据通过友好的页面展示出来,提供实时分析的功能。
# 2.5 Kibana (opens new window)
# 概述
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成Kibana安装并启动Elasticsearch索引监测。
# 下载 (opens new window)

Kibana 版本要和 Es 一致!
# 解压目录

# 启动
双击 bin 目录下 kibana.bat

# 访问
http://localhost:5601

# 测试工具

开发工具! (Post、curl、head、谷歌浏览器插件测试!)
# 汉化
- 在
x-pack\plugins\translations\translations\zh-CN.json已有中文设置
{
"messages": {
"common.ui.aggResponse.allDocsTitle": "所有文档",
"common.ui.aggResponse.fieldLabel": "字段",
"common.ui.aggResponse.valueLabel": "值",
"xpack.watcher.watchEdit.thresholdWatchExpression.aggType.fieldIsRequiredValidationMessage": "此字段必填。",
"xpack.watcher.watcherDescription": "通过创建、管理和监测警报来检测数据中的更改。"
}
}
2
3
4
5
6
7
8
9
- 修改
config\kibana.yml
# Specifies locale to be used for all localizable strings, dates and number formats.
# Supported languages are the following: English - en , by default , Chinese - zh-CN .
#i18n.locale: "en"
i18n.locale: "zh-CN"
2
3
4
- 访问

# 3. ES核心概念
索引
字段类型(mapping)
文档(documents)
elasticsearch是
面向文档,关系行数据库 和 elasticsearch 客观的对比!一切都是JSON!
# 3.1 关系行数据库 和 elasticsearch
Relational DB [MySQL] | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | 类型(types) [会被弃用] |
| 行(rows) | 文档(documents) |
| 字段(columns) | 域(fields) |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多 个文档(行),每个文档中又包含多个字段(列)。
# 3.2 逻辑设计
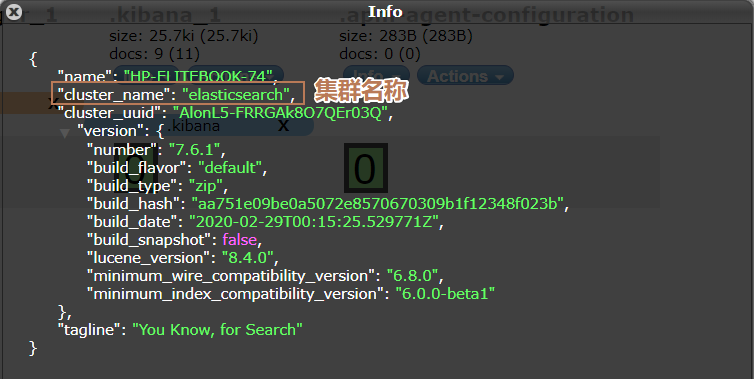
elasticsearch 在后台把每个索引划分成多个分片,每分分片可以在集群中的不同服务器间迁移
一个elasticsearch 就是一个集群!默认的集群名称就是 elaticsearh
# 3.3 逻辑设计
一个索引类型中,包含多个文档,比如说文档1,文档2。 当我们索引一篇文档时,可以通过这样的一各顺序找到 它: 索引 ▷ 类型 ▷ 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意:ID不必是整数,实际上它是个字符串。
# 文档
就是一条数据
就是我们的一条条数据
user
1 zhangsan 18
2 kuangshen 3
2
3
4
5
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是 "文档",elasticsearch中,文档有几个 重要属性 :
自我包含,一篇文档同时包含字段和对应的值,也就是同时包含 key:value!
可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的! {就是一个json对象!fastjson进行自动转换!}
灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符 串也可以是整形。因elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
# 类型

类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。 类型中对于字段的定义称为映射,比如 name 映 射为字符串类型。 我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。 但是elasticsearch也可能猜不对, 所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
# 索引
就是数据库!
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。 然后它们被存储到了各个分片上了。
 豫公网安备 41048202000165号
豫公网安备 41048202000165号