
 ElasticSearch-IK分词器
ElasticSearch-IK分词器
# ElasticSearch-IK分词器
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词
使用中文,建议使用ik分词器!
IK提供了两个分词算法:
ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分!
# 1. 下载
# 2. 部署
安装
解压,放在 ES 中的 plugins 的 ik 目录下
重启,访问
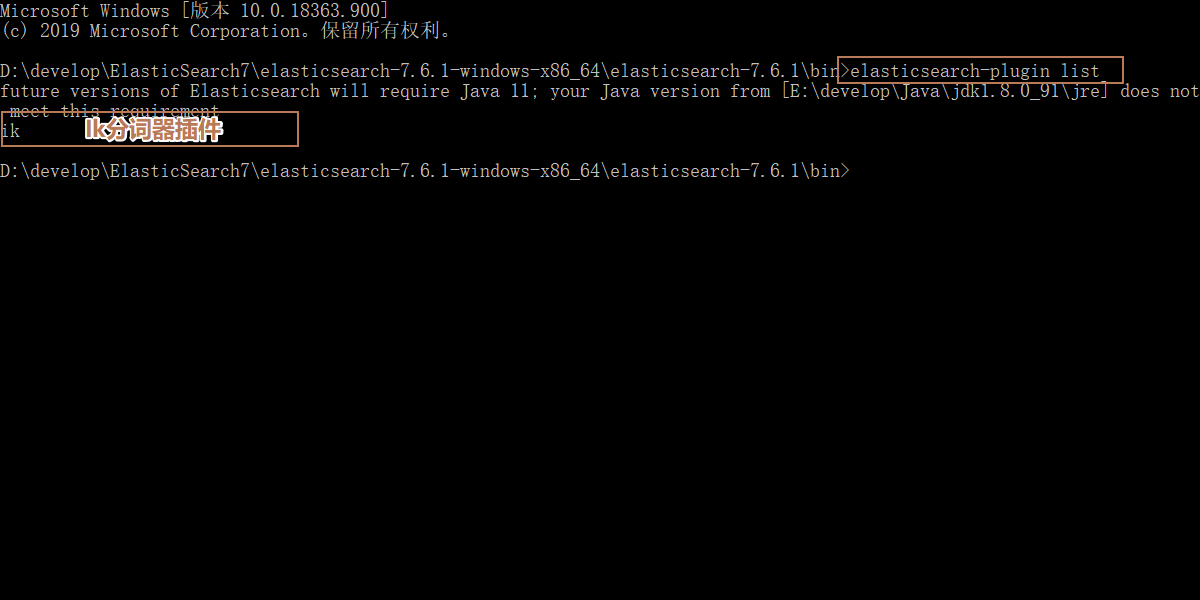
- 加载插件

- 查看es的插件
elasticsearch-plugin list
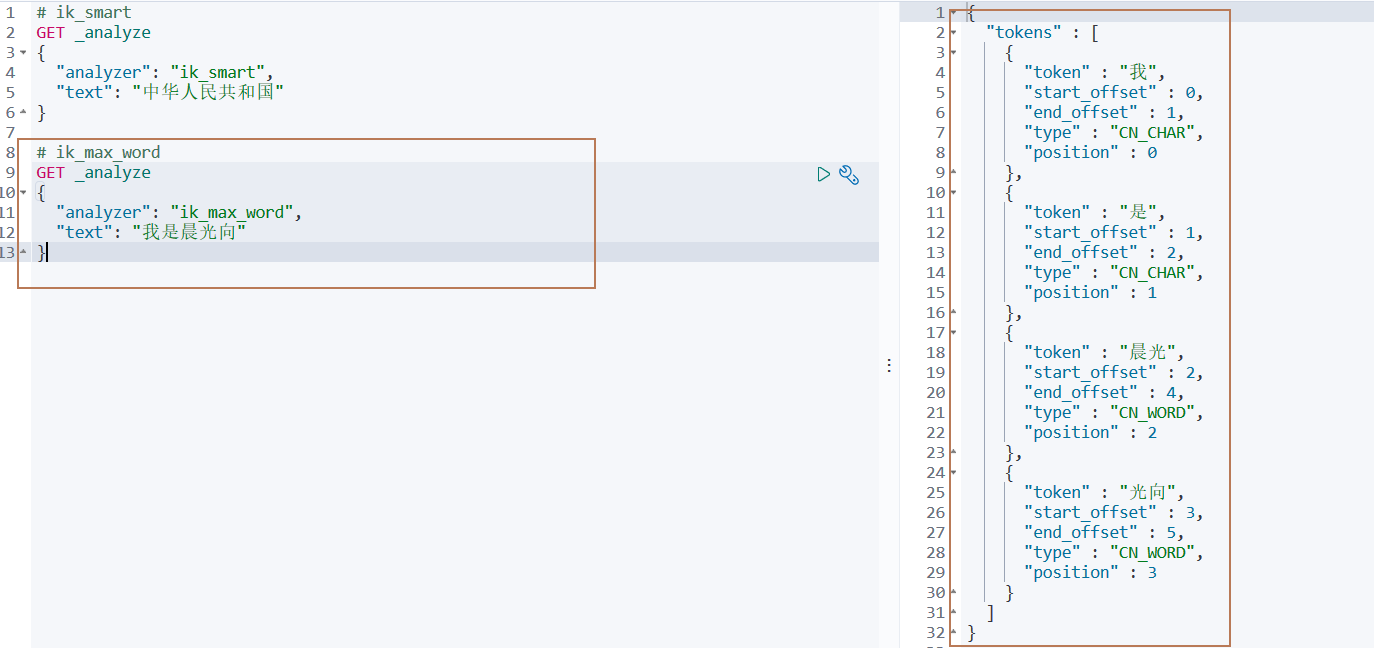
# 3. Kibana测试
# ik_smart分词
ik_smart 为最少切分

# ik_max_word分词
ik_max_word为最细粒度划分!
GET _analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国"
}
1
2
3
4
5
2
3
4
5
- 结果
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# 4. 自定义分词器的字典
# 问题:
当输入我是晨光向时没有我们想要的晨光向这个分词
# 解决
ik 分词器增加自己的 !
在 elasticsearch-7.6.1\plugins\ik\config 下配置
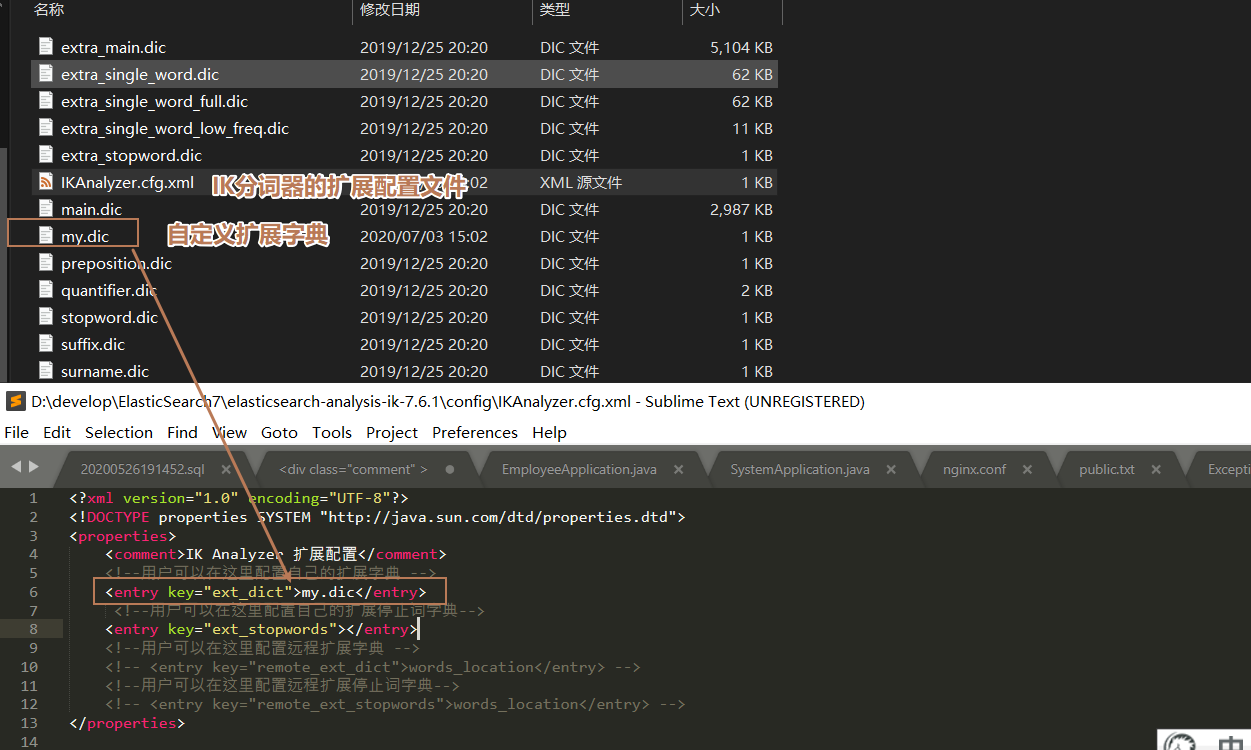
my.dic
晨光向
1
# 重启
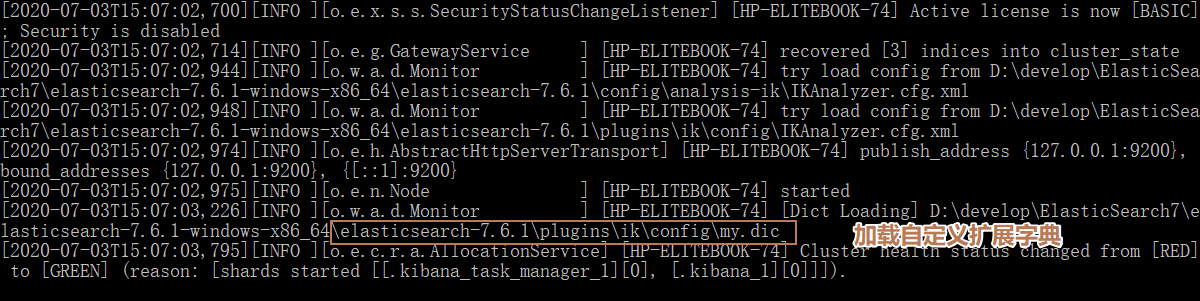
# Kibana结果

以后的话,我们需要自己配置 分词就在自己定义的dic文件中进行配置即可!
上次更新: 2023/04/11, 22:23:48
 豫公网安备 41048202000165号
豫公网安备 41048202000165号